Demystifying RCE Vulnerabilities in LLM-Integrated Apps Review
Demystifying RCE Vulnerabilities in LLM-Integrated Apps
: Tong Liu1,2, Zizhuang Deng1,2, Guozhu Meng1,2,∗, Yuekang Li3, Kai Chen1
지난 논문에 대한 연장선으로 해당 논문 꼭 읽어보고 싶었다.
읽기 전에는 아카이브에 올라와 있는 논문은 검증이 안된 논문이 많다고 하여, 고민을 했지만 조금 들여다 봤을 때는 관심 있게 볼 만한 내용이라고 생각한다.
최근 대형 언어 모델(LLM)은 다양한 작업에서 놀라운 성과를 보이며, 이를 기반으로 한 통합 프레임워크와 웹 애플리케이션이 다수 개발되었다. 그러나 일부 프레임워크는 원격 코드 실행(RCE) 취약점을 가지고 있어, 공격자가 프롬프트 인젝션을 통해 앱 서버에서 임의의 코드를 실행할 수 있다. 이러한 취약점의 심각성에도 불구하고 이를 체계적으로 조사한 연구는 부족한 상황이다.
이를 해결하기 위해, LLMSMITH라는 도구를 기반으로 두 가지 전략을 제시했다:
- 정적 분석 도구: 프레임워크의 소스 코드를 분석해 잠재적인 RCE 취약점을 탐지.
- 프롬프트 기반 자동화 테스트: LLM 통합 웹 애플리케이션의 취약점을 검증.
연구 결과:
- 6개 프레임워크에서 총 13개의 취약점을 발견(12개의 RCE, 1개의 임의 파일 읽기/쓰기 취약점).
- 7개의 CVE ID를 부여받았으며, 프레임워크 개발자가 11개의 취약점을 확인.
- 51개 앱 중 17개에서 취약점 확인(16개는 RCE, 1개는 SQL Injection).
또한, RCE를 통해 앱 사용자에게 영향을 미치는 공격(예: 응답 조작, API 키 유출) 가능성을 시연하고, 프레임워크 및 앱 개발자를 위한 보안 완화 방안을 제안했다. 이 연구는 LLM 통합 앱과 프레임워크의 보안 취약점에 대한 인식을 높이고 문제 해결에 기여하는 데 목적이 있다.
목차
1. Introduction
2. Background & Problem Statement
2.1 LLM- Integrated Frameworks and Apps
2.2 LLM security
2.3 Problem Statement
3. 접근법
3.1 Vulnerable Framework API Detection
3.2 White-Box App Scanning
3.3 Black-Box App Searching
3.4 Automated Prompt-Based Exploitation
4. Evaluation
4.1 Detection Accuracy of Vulnerable APIs
4.2 Effectiveness in White-Box LLM App Scanning
4.3 Effectiveness in Black-Box LLM App Searching
4.4 Successful Prompt Attacks
5. Measurements
5.1 Measurement of Vulnerabilities in LLM Frameworks
5.2 Measurement of Real-World LLMIntegrated Apps
5.3 New Practical Real-world Attacks
6. Related Work
7. Discussion
8. Conclusion2.1 LLM- Integrated Frameworks and Apps
Langchain, LlamInde와 같은 프레임워크는 개발자에게 많은 편의성을 제공하며, 유연한 추상화, 광범위한 툴킷, 데이터분석 활용 등 많은 분야에서 LLM은 도움을 주고 있다는 내용을 담고 있다.
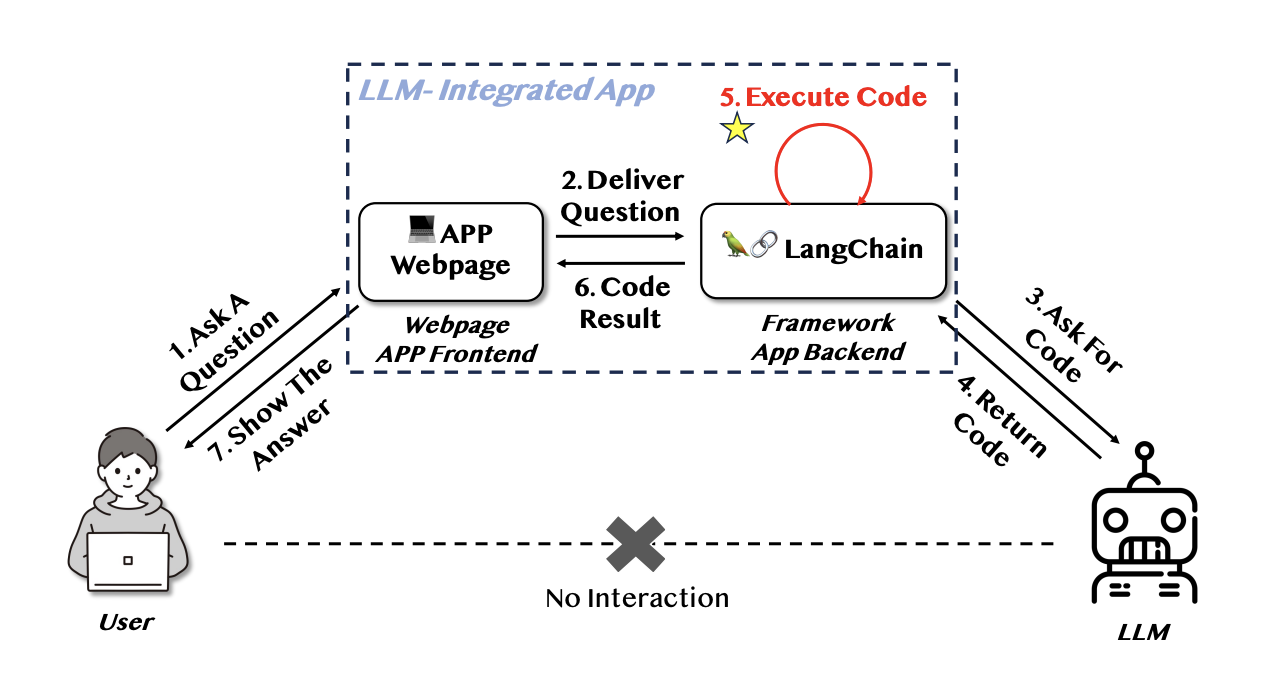
위 그림은 코드 실행을 포함하는 LLM 통합 웹 앱의 간단한 워크플로우.
문제 해결을 위한 코드 생성, 코드 실행 및 결과 확인 등의 작업 순서를 거쳐 하위 작업을 연결하여 사용자의 문제 요구 사항을 충족시키는 역할을 한다.
2.2 LLM Security
대형 언어 모델(LLM)의 엄청난 성공은 공격자와 보안 분석가 모두의 관심을 끌고 있다. LLM과 그 파생 기술의 보안에 대한 관심이 점점 더 커지고 있다. 기존의 신경망과 마찬가지로 LLM 역시 적대적 예제(adversarial examples), 백도어(backdoor), 그리고 개인정보 유출에 취약하다. 적대적 프롬프트(adversarial prompting)의 정의에 따르면, LLM을 대상으로 하는 세 가지 새로운 유형의 공격이 있다.
프롬프트 인젝션(prompt injection), 프롬프트 누출(prompt leaking), 제약 우회(jailbreaking).
- 프롬프트 인젝션 : 프롬프트 인젝션은 프롬프트를 활용해 LLM의 시스템 프롬프트를 직접적으로 탈취하는 공격을 말한다. 이는 프롬프트 엔지니어링을 통해 구현될 수 있다. 많은 적대적 프롬프트는 특정 템플릿을 따르는데, 대표적인 예로 이전 요청을 무시하고, [새로운 작업]을 수행하라”라는 형식이 있다. LLM의 관점에서 보면, 해당 프롬프트는 “[시스템 프롬프트]. 이전 요청을 무시하고, [새로운 작업]을 수행하라”와 같이 연결된다. 이로 인해 LLM은 기존의 시스템 프롬프트를 무시하고 새로운 지시를 실행하게 되어, 결과적으로 출력이 공격자의 의도대로 조작된다.
샌드박스는 일반적으로 크기가 커서 경량 애플리케이션 배포에는 적합하지 않다. 또한, 샌드박스 내에서 엄격한 제한을 적용하면 프레임워크의 기능적 완전성에 영향을 미칠 가능성도 있다. 이 상황을 더욱 흥미롭게 만드는 점은, 기존의 애플리케이션 취약점 악용과 달리 이러한 공격에서 사용되는 페이로드가 오직 자연어 표현으로만 구성된다는 것이다. 이는 컴퓨터 보안에 대한 깊은 지식이 없는 공격자조차도 언어 기반 취약점을 이용해 원격 코드 실행(RCE) 공격을 쉽게 수행할 수 있음을 의미한다.
3. Approach
LLMSMITH라는 Auto Tool을 이용해서 LLM 통합 프레임워크와 앱의 취약점을 탐지하는 방법을 설명하고 있다.
해당 내용을 간단하게 요약하자면 아래와 같다.
요약
- LLMSMITH의 구조와 접근 방식
- LLMSMITH는 네 가지 주요 모듈로 구성된다:
- 취약 API 탐지: 정적 분석을 통해 위험한 함수(e.g., eval, exec)로 연결되는 호출 체인을 추출.
- 화이트박스 앱 스캐닝: GitHub에서 소스 코드를 기반으로 앱을 검색하고 테스트 후보를 수집.
- 블랙박스 앱 검색: 화이트박스 앱의 설명에서 키워드를 추출하고 이를 바탕으로 앱 마켓에서 관련 앱을 탐색.
- 프롬프트 기반 자동 익스플로잇: 미리 설계된 테스트 프롬프트를 사용하여 앱의 취약점을 단계별로 분석.
- LLMSMITH는 네 가지 주요 모듈로 구성된다:
- 취약 API 탐지
- LLM 통합 프레임워크에서 사용자 API가 노출된 매개변수(e.g., 프롬프트)를 통해 RCE를 유발할 가능성이 있는 경우, 이를 취약 API로 정의.
- 정적 분석을 통해 사용자 API에서 위험한 함수로 연결되는 호출 체인을 추적하여 취약성을 탐지.
- 예시: LangChain 프레임워크의 exec 호출 체인을 분석하여 취약점을 발견.
- 암묵적 호출 처리
- 일부 호출 체인은 직접적으로 호출되지 않고 암묵적으로 연결됨.
- 이를 해결하기 위해 LLMSMITH는 암묵적 호출을 식별하고 호출자를 추적하는 과정을 반복적으로 수행하여 호출 체인을 완성.
- 취약성 검증
- 발견된 호출 체인의 정확성을 검증하고, 실제 사용 사례와 일치하는 PoC(Proof of Concept)를 작성하여 실질적인 취약성을 확인.
핵심적으로는 LLMSMITH는 정적 분석과 자동화된 프롬프트 기반 테스트를 통해 LLM 통합 프레임워크와 앱의 취약점을 탐지한다. 특히, 호출 체인 분석과 암묵적 호출 탐지를 통해 복잡한 코드베이스에서도 RCE를 유발할 수 있는 취약 API를 효율적으로 식별하며, 이를 실제 사례에 기반하여 검증한다.
3.3 Black-Box App Searching
블랙박스 앱의 소스 코드를 접근할 수 없는 한계로 인해 기존의 API 코드를 검색하는 방법은 적용이 불가능하며, 블랙박스 테스트 대상을 찾는 데 큰 어려움이 있다. 이를 해결하기 위해 우리는 화이트박스 앱 스캐닝에서 얻은 사전 지식을 활용한 검색 방식을 제안한다. 이 과정에서 LLMSMITH는 화이트박스 앱 저장소의 설명에서 키워드를 추출한다. 각 키워드에는 문장에서의 중요도를 나타내는 점수가 할당된다. 이러한 키워드를 사용하여 애플리케이션 마켓(e.g., There's an AI For That)에서 블랙박스 테스트 대상을 검색한다.
알고리즘 1에서는 키워드 추출 방법의 주요 과정을 자세히 설명한다. 저장소 설명에서 추출된 방대한 키워드 중 가장 가치 있는 인사이트를 얻기 위해 LLMSMITH는 README와 추출된 키워드를 말뭉치로 사용하여 Word2Vec 모델을 학습시킨다~~. 동일한 키워드가 다른 텍스트에서 추출되면 점수를 합산해 업데이트한다. 그런 다음, 키워드의 워드 벡터를 활용해 코사인 유사도를 계산하여 유사도 행렬을 생성한 후~~, **K-평균 군집화(K-Means Clustering)**를 수행한다. 각 클러스터에서 점수가 가장 높은 상위 n개의 키워드를 선택하여 정제된 키워드 집합을 생성한다.


LLMSMITH는 화이트박스 앱에서 얻은 설명 데이터를 기반으로 키워드를 추출하고, 이를 활용해 블랙박스 앱 테스트 대상을 효율적으로 검색하는 방법을 제안한다. 키워드는 Word2Vec 모델로 학습되어 중요도를 점수화하고, 코사인 유사도 및 K-평균 군집화를 통해 정제된다. 이후 정제된 키워드를 조합하여 앱 마켓에서 블랙박스 앱을 검색하며, 구체적인 키워드 조합을 통해 검색 효율을 극대화한다.
3.4 Automated Prompt-Based Exploitation
LLMSMITH의 자동화된 익스플로잇 접근법을 설명하며, 앱의 취약점을 점진적으로 분석하고 악용하는 과정을 다룬다.
- 목적: 앱의 프롬프트 응답을 분석하여 취약점을 탐지하고 이를 자동으로 악용.
- 전략: 사전에 설계된 프롬프트를 사용하여 앱과 상호작용하며, 단계별로 취약성을 테스트.

주요 테스트 단계
- 기본 기능 테스트
- 간단한 계산이나 출력(print)과 같은 기본 기능이 정상 작동하는지 확인.
- 헛소리(hallucination) 테스트
- 무작위 문자열의 해시 계산과 같은 작업을 수행하도록 테스트하여 앱이 코드 실행 기능을 갖췄는지 확인.
- 이 단계에서 LLM의 헛소리로 인해 발생할 수 있는 간섭을 줄임.
- RCE 테스트 (Jailbreak 없이)
- ls, env, id 등의 시스템 명령어를 실행하도록 유도.
- 결과가 예상대로 나오면 네트워크 테스트로 진행하고, 실패하면 Jailbreak 기술로 전환.
- Jailbreak 기술 활용
- LLM Jailbreak: LLM의 초기 제한을 우회하여 원하는 출력이 나오도록 유도.
- 코드 Jailbreak: 프레임워크에서 제공하는 샌드박스 제한을 회피하고, 악성 코드 구조 탐지를 피한 뒤 샌드박스를 탈출하여 명령 실행.
- 네트워크 테스트
- 앱이 외부 네트워크와 연결 및 데이터 전송이 가능한지 확인.
- curl 명령어를 사용해 공격자 서버로 요청을 보내고, 수신된 연결이 있으면 앱의 네트워크 접근 가능성을 확인.
- 백도어 테스트
- 프롬프트 인젝션을 통해 공격자가 준비한 백도어 스크립트를 앱이 다운로드 및 실행하도록 강제.
- 리버스쉘(reverse shell) 등의 행동이 발생하는지 확인.
최종 목표
- 앱이 코드 실행(RCE), 네트워크 접근, 백도어 삽입 등 다양한 공격 시나리오에 얼마나 취약한지 평가.
- 앱의 보안 상태를 종합적으로 진단하여 취약점 악용 가능성을 극대화.
4.1 Detection Accuracy of Vulnerable APIs
LLMSMITH가 LLM 통합 프레임워크에서 호출 체인을 추출하고 분석한 결과와 이를 다른 도구(PyCG)와 비교한 내용을 다룬다.
- LLMSMITH의 호출 체인 분석 결과
- 6개의 LLM 통합 프레임워크에서 총 38개의 호출 체인, 10개의 고수준 사용자 API, 13개의 취약점을 추출.
- 검증 결과, 38개의 호출 체인 중 32개가 임의 코드 실행(RCE, LCE 포함)을 유발할 수 있음.
- 나머지 6개는 다음 이유로 실행 불가능:
- 함수 이름 혼동: 함수 이름 변경 및 재포장으로 인해 잘못된 호출 체인이 식별됨.
- 매개변수 제어 불가능: 위험한 함수의 매개변수가 제어되지 않아 코드 실행이 차단됨.
- 보호 메커니즘: 일부 프레임워크는 Docker 컨테이너에서 Python 코드를 실행하여 환경을 격리, 호스트 데이터 및 권한 접근을 차단.
- LLMSMITH vs PyCG 비교
- PyCG: LangChain(1600개 파일)과 LlamaIndex(440개 파일)의 호출 그래프 추출 시, 분석 시간 초과(1시간 이상 소요)로 실패.
- LLMSMITH: 38개의 호출 체인을 성공적으로 추출.
- PyCG는 API 가이드 없이 개별 파일을 분석해야 하므로 제한적 결과(7개의 호출 체인만 추출)를 제공.
참고하시읭 결론 : LLMSMITH는 호출 체인 추출 및 분석에서 PyCG보다 훨씬 효율적이며, 복잡한 코드베이스에서도 높은 정확도로 취약점을 탐지할 수 있다.
Black Box, White Box LLM APP Searching에 대한 상세 내용은 본문을 참고하길 바란다. 4.1부터 4.4까지를 참고하면 된다.
검증과 효과성에 대한 내용은 가볍게 블로그로 다룰만한건 아닌것 같기도 하고, 시연 등 여러 챕터가 남아 있기도 하다. 그리고 상당히 광범위하게 적용되는 만큼 신중하게 접근이 필요하기도 하다. 토론과 결론을 담고 끝내고자 한다.
7. Discussion
토론 부분에서는 LLMSMITH로 발견된 취약점에 대한 개발자들의 대응 및 이를 완화하기 위한 제안과 향후 연구 방향을 설명하고 있다. 아래는 본문의 내용을 요약해서 설명한다.
1. 개발자들의 대응
- 취약점 보고와 응답:
- 5개의 취약한 프레임워크 중 4개는 GitHub를 통해 문제를 보고한 후 1~2일 이내에 응답.
- pandas-ai는 하루 만에 패치를 시도했으나, LlamaIndex는 아직 문제를 해결하지 않음.
- 앱 관련 취약점 보고 중 7건은 응답이 없었으며, 이는 앱 유지보수에 대한 개발자의 무관심을 시사.
- 평균 응답 시간은 2~3일이며, chat pandas는 2시간 내로 대응 및 완화 조치를 구현.
2. 완화 방안
- 권한 관리:
- 최소 권한 원칙(Principle of Least Privilege, PoLP)을 적용.
- 앱과 시스템 파일의 읽기/쓰기 권한을 비활성화.
- SUID 및 기타 민감한 명령 실행을 차단.
- 환경 격리:
- seccomp 및 setrlimit와 같은 도구를 사용해 프로세스 및 리소스를 격리.
- Pypy나 IronPython과 같은 보안 강화 Python 인터프리터를 활용해 샌드박싱 구현.
3. 향후 연구 방향
- 다중 언어 지원:
- 현재 LLMSMITH는 Python 기반 프레임워크에만 적용 가능하며, Rust(Chidori)나 TypeScript(Axilla)와 같은 다른 언어의 프레임워크로 확장 계획.
- 취약점 유형 확장:
- 현재는 RCE 탐지에 초점이 맞춰져 있으나, 향후 SQL Injection, 데이터 유출 등 다양한 취약점 유형으로 탐지 범위를 확대.
- 실제 환경에서의 테스트 적용성 강화.
개발자들의 대응 속도는 다소 차이가 있지만, 전반적으로 취약점 해결에 대한 우선순위가 낮은 경향이 있다. 이를 보완하기 위해 권한 관리와 환경 격리를 포함한 완화 방안을 제안하며, LLMSMITH의 기능 확장과 다중 언어 지원을 통해 더 많은 취약점을 탐지할 계획이다.
8. Conclusion
LLM 통합 프레임워크와 앱을 효율적으로 테스트하기 위해 LLMSMITH라는 접근 방식을 제안했다. LLMSMITH는 정적 분석, 자연어 처리(NLP), 제약 우회(jailbreaking) 기술을 통합하여 프레임워크와 앱을 효과적으로 테스트한다.
- 프레임워크 테스트 결과: 6개 프레임워크에서 총 13개의 취약점을 발견했으며, 이 중 7개는 CVE를 부여받았고 심각도는 9.8로 평가되었다.
- 앱 테스트 결과: 51개의 실제 앱 중 17개가 취약점이 있었고, 이 중 16개는 원격 코드 실행(RCE)이 가능했다.
또한, RCE 성공 후 공격 범위를 확장하여 다른 사용자에게 영향을 미칠 수 있는 두 가지 새로운 공격 방법을 제안했다. 이러한 RCE 취약점을 완화하기 위한 실질적인 방안도 소개했다. 이 연구는 LLM 통합 앱에서 RCE 취약점을 체계적으로 분석한 최초의 연구로 평가된다.
한 주 화이팅!
긴 글 읽어주셔서 감사합니다. :)
앙뇽 -