
- elasticsearch
- aiinterviewprep
- llm hacking
- llmexplained
- ai prompt
- airesearch
- 보안뉴스
- aiforbeginners
- largelanguagemodels
- llm questions
- AI질문
- 정보보안
- 프롬프트엔지니어링
- ai입문
- aiengineer
- prompt injection
- xz-utils
- llm attack
- PromptEngineering
- llminterviewquestions
- ai hacking
- AI기초
- ChatGPT
- metasploit_series
- Security
- MachineLearning
- llm 활용
- llm활용
- llm model
- ai vulnerability
- Today
- Total
ARTIFEX ;)
[Chapter 3] AI 전문가를 향한 첫 걸음 : LLM Interview Questions 핵심 50가지 QnA! 본문
[Chapter 3] AI 전문가를 향한 첫 걸음 : LLM Interview Questions 핵심 50가지 QnA!
Artifex_Ethan_ 2025. 6. 12. 18:01안녕하세요 !!!
와 티스토리 블로그 쓰면서 접은글을 사용해봤는데 지금까지 전혀 몰랐어요 ... 글이 다 더보기로 접히더라구요 ...
힝 ㅠㅠ

앞으로는 접은글 안쓰고 그냥 써야겠어요 다 가려져서 깜짝 놀랐어요 ㅠㅠ
이렇게요.. 더보기를 클릭해야 하더라구요 ㅠㅠ
Anyway! 우리는 마저 QnA 내용을 봐야겠죠~!!
Chapter 1, 2는 아래 링크를 확인해주세요
https://kangmin517.tistory.com/entry/Chapter-1-AI-%EC%A0%84%EB%AC%B8%EA%B0%80%EB%A5%BC-%ED%96%A5%ED%95%9C-%EC%B2%AB-%EA%B1%B8%EC%9D%8C-LLM-Interview-Questions-%ED%95%B5%EC%8B%AC-50%EA%B0%80%EC%A7%80-QnA
[Chapter 1] AI 전문가를 향한 첫 걸음 : LLM Interview Questions 핵심 50가지 QnA!
안녕하세요! 여러분의 공부에 도움이 될만한 것들을 알려드리는 MINI입니다.요즘 어딜 가나 'LLM', '생성형 AI' 이야기가 들려오죠. ChatGPT로 리포트 초안을 만들고, 번역기를 돌려 해외 자료를 보고,
kangmin517.tistory.com
[Chapter 2] AI 전문가를 향한 첫 걸음 : LLM Interview Questions 핵심 50가지 QnA!
안녕하세요!여러분에게 도움을 드리고자 준비해 온 MINI입니다![Chapter 2]로 바로 이어서 설명 드리겠습니다. [Chapter 1]에서 바로 이어지는 글이다보니, 별도 사전 설명 없이 진행하도록 하겠습니다
kangmin517.tistory.com

이번 파트에서는 LLM의 심장인 트랜스포머 아키텍처 내부의 수학적 원리와 핵심 개념들을 조금 더 깊게 들여다보겠습니다. 수식이 조금 포함되어 있지만, 최대한 쉽게 풀어서 설명해 드릴게요.
Q21. 위치 인코딩(Positional Encodings)은 무엇이고 왜 사용되나요?
A21. 위치 인코딩은 트랜스포머의 입력값에 단어의 순서 정보를 더해주는 역할을 합니다.
트랜스포머의 핵심인 셀프 어텐션 메커니즘은 문장 내 모든 단어를 동시에 보기 때문에, 자체적으로는 단어의 순서를 인식하지 못하는 단점이 있습니다.
사인, 코사인 같은 삼각함수나 학습 가능한 벡터를 사용하여 각 토큰의 위치 정보를 부여합니다. 이를 통해 "왕"과 "왕관" 같은 단어들이 문장 내 위치에 따라 올바르게 해석될 수 있으며, 이는 특히 기계 번역과 같은 작업에서 매우 중요합니다.
Q22. 멀티 헤드 어텐션(Multi-head Attention)은 무엇이고 LLM을 어떻게 향상시키나요?
A22. 멀티 헤드 어텐션은 쿼리, 키, 밸류 벡터를 여러 개의 작은 하위 공간으로 나누어, 모델이 입력 정보의 여러 측면을 동시에 집중해서 볼 수 있게 하는 기법입니다. 한 문장을 보더라도 어떤 '헤드(head)'는 문법적 구조에 집중하고, 다른 헤드는 의미적 관계에 집중하는 식이죠. 이처럼 여러 관점에서 정보를 종합함으로써 모델이 더욱 복잡하고 미묘한 패턴을 포착하는 능력을 향상시킵니다.
Q23. 어텐션 메커니즘에서 소프트맥스(softmax) 함수는 어떻게 적용되나요?
A23. 소프트맥스 함수는 어텐션 점수를 확률 분포로 정규화하는 역할을 합니다. 어텐션 메커니즘에서는 쿼리-키 벡터의 내적(dot product)을 통해 계산된 원시 유사도 점수를 입력받아, 합이 1이 되는 가중치로 변환합니다.

이 과정을 통해 모델이 문맥상 중요한 특정 토큰에 더 집중하도록 만들어, 입력의 핵심적인 부분에 초점을 맞추게 됩니다.
Q24. 내적(dot product)은 셀프 어텐션에 어떻게 기여하나요?
A24. 셀프 어텐션에서 내적은 쿼리(Q)와 키(K) 벡터 사이의 유사도 점수를 계산하는 데 사용됩니다.
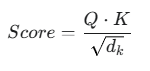
이 점수가 높을수록 두 토큰의 관련성이 높다는 것을 의미합니다. 이 방식은 매우 효율적이지만, 시퀀스 길이가 길어질수록 계산량이 제곱으로 늘어나는 $(O(n^{2}))$ 복잡도를 가지는 단점이 있습니다.
이 때문에 긴 시퀀스를 처리하기 위한 희소 어텐션(sparse attention) 같은 대안 연구가 활발히 이루어지고 있습니다.
Q25. 언어 모델링에서 교차 엔트로피 손실(Cross-Entropy Loss)이 사용되는 이유는 무엇인가요?
A25. 교차 엔트로피 손실은 모델이 예측한 토큰의 확률 분포와 실제 정답 토큰의 확률 분포 사이의 차이를 측정하는 함수입니다.
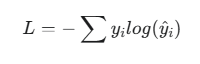
이 함수는 모델이 틀린 예측을 할수록 더 큰 페널티를 부과하여, 모델이 정답 토큰을 정확히 선택하도록 유도합니다. 언어 모델링에서는 이 손실 함수를 최소화하는 과정을 통해, 모델이 다음으로 올바른 토큰에 높은 확률을 할당하도록 만들어 전반적인 성능을 최적화합니다.
Q26. LLM에서 임베딩의 그래디언트(gradient)는 어떻게 계산되나요?
A26. 임베딩에 대한 그래디언트는 역전파(backpropagation) 과정에서 연쇄 법칙(chain rule)을 사용하여 계산됩니다.
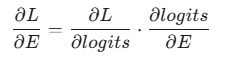
이 그래디언트는 손실(loss)을 최소화하는 방향으로 임베딩 벡터를 조정하는 역할을 합니다. 이 과정을 반복하며 단어의 의미적 표현이 더욱 정교해지고, 결과적으로 과제 수행 성능이 향상됩니다.
Q27. 트랜스포머의 역전파에서 자코비안 행렬(Jacobian matrix)은 어떤 역할을 하나요?
A27. 자코비안 행렬은 출력값에 대한 입력값의 편도함수(partial derivatives)를 모아놓은 행렬입니다. 트랜스포머에서는 다차원의 출력값에 대한 그래디언트를 계산하는 데 도움을 줍니다. 이를 통해 역전파 과정에서 가중치와 임베딩이 정확하게 업데이트되도록 보장하며, 복잡한 모델을 최적화하는 데 매우 중요한 역할을 합니다.
Q28. 고유값(eigenvalues)과 고유벡터(eigenvectors)는 차원 축소와 어떤 관련이 있나요?
A28. 고유벡터는 데이터가 어떤 주된 방향으로 분포되어 있는지를 나타내고, 고유값은 그 방향으로 데이터가 얼마나 넓게 퍼져있는지(분산)를 나타냅니다.
주성분 분석(PCA)과 같은 차원 축소 기법에서는 고유값이 큰 고유벡터들, 즉 데이터의 분산을 가장 잘 설명하는 방향들만 선택합니다. 이를 통해 데이터의 손실을 최소화하면서 차원을 줄일 수 있고, LLM의 입력 데이터를 효율적으로 표현하는 데 사용될 수 있습니다.
Q29. KL 발산(KL Divergence)이란 무엇이며 LLM에서 어떻게 사용되나요?
A. 쿨백-라이블러 발산(Kullback-Leibler Divergence), 줄여서 KL 발산은 두 확률 분포가 얼마나 다른지를 정량적으로 측정하는 지표입니다.
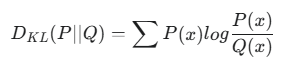
LLM에서는 모델의 예측 결과(Q)가 실제 데이터의 분포(P)와 얼마나 유사한지를 평가하는 데 사용됩니다. 파인튜닝 과정에서 이 값을 줄여나감으로써, 모델의 결과물이 목표 데이터와 더욱 유사해지도록 유도하고 출력의 품질을 향상시킬 수 있습니다.
Q30. ReLU 함수의 미분은 무엇이며 왜 중요한가요?
A. ReLU(Rectified Linear Unit) 함수 $f(x)=max(0,x)$의 미분값은 다음과 같습니다.
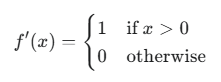
ReLU는 계산이 매우 간단하고, 특정 조건에서 미분값이 1 또는 0이 되는 희소성(sparsity)과 비선형성(non-linearity) 덕분에 그래디언트 소실 문제(vanishing gradients)를 방지하는 데 효과적입니다. 이러한 특징 덕분에 계산 효율이 높고 훈련이 안정적이어서 LLM에서 널리 사용됩니다.
알고 있는 개념이나 모르는 것들도 많아요!
Chapter 1에서 말한것처럼 기본 개념을 위한 글이다보니까 상세한 설명은 나중에 기회가 되면 하나씩 뜯으면서 해볼게요!
다음에 다시 돌아오겠습니다!
앙뇽



